使用Clip模型与Qdrant搭建一个AI驱动的图片搜索引擎
引入
在上次的项目中,我们介绍了如何使用图像哈希与VP树快速从一组图片中找出相似的图片。但是,这种方法有一个缺点,就是图像哈希并不可以理解图片本身的视觉信息。因此,这种方法的用途只用重复(或者极为相似)图片的搜索,而无法用于搜索与给定图片内容相似的图片,因此没法用在图片搜索引擎中。
设想一下我们想要实现这样的需求,给定一张图片,我们的服务可以检索出与它相似的图片(在风格、内容等方面相似)。同时,我们甚至可以给定一段文字,让服务返回与这段文字描述的图片相似的图片。 在这种需求下,你可能想通过一个图像分类模型来实现,但是传统的图像分类模型(例如ResNet, YOLO, ViT等)都是基于ImageNet等数据集进行监督学习的,需要大量标注好的数据集才能训练,且这些模型只能对数据集中包含的类别进行比较有效的分类,对于数据集以外的类别,这些模型所具备的泛化能力较差。因此,这些模型并不适合用于我们的需求。
而在我们本文中所使用的CLIP模型,则可以很好地实现Zero-shot image classification。
Embedding简介
在数据科学中,我们经常使用一个“特征向量”来代替一个抽象的对象本身(例如一段文本、一张图片、一段音频、一个用户的个性化推送数据:D)来实现对这个对象的描述。 这个特征向量可以用来表示这个对象的某些特征,例如这个对象的内容、风格、情感等等。这个特征向量通常是通过一个神经网络模型(例如BERT、ResNet等)的前向传播过程得到的,我们称这个过程为“Embedding”。
一般来讲,特征相似的对象在特征空间中的距离也会比较近,这样我们就可以通过计算这些特征向量的距离来判断这些对象之间的相似度。 Embedding的长度是由模型的设计决定的,一般在384~1024维不等(本文中使用的Clip ViT-B/32的Embedding长度为768),一般来说,Embedding的长度越长,这个特征向量所包含的信息也就越多,但是推理、比较、索引等等所需的计算资源也会增加。
Embedding广泛用于各种领域,例如搜索引擎、推荐系统等等。我们平常恨之入骨的个性化广告推送很多就是利用Embedding技术完成的。
不同embedding的对比
比较不同embedding的方式与推理该Embedding的模型有关,一般都是采用余弦相似度(Cosine Similarity)来计算两个Embedding之间的相似度。 Cosine Similarity是通过计算两个向量的夹角的余弦值来判断两个向量的相似度的方法。假设两个向量分别为和,则两个向量的余弦相似度为:
如果我们对向量进行了归一化处理(即使其模长均为1),那么余弦相似度的计算就可以简化为两个向量的点乘运算:
所得的值在[-1, 1]之间,值越大表示两个向量越相似,对于Embedding来说则代表两个对象之间的相似度越高。
向量数据库
虽然向量相似度的计算非常简单,要索引大量的向量并可以以较低复杂度完成对向量的相似查找是非常困难的。幸运的是,已经有大量的向量数据库(Vector Database)帮我们造好了轮子,向量数据库一般都是基于一种数据结构(例如VP树、HNSW等)来实现的,这些数据结构可以在高维空间中高效地完成向量的索引、查找等操作。
常见的向量数据库有Qdrant, milvus, redis, elasticsearch(如果它能算数据库的话), 等等。一般来讲,向量数据库都属于NoSQL数据库的一种,它们不太适合用于存储和检索结构化数据,但是对于向量数据来说,向量数据库是非常高效的。如果你的应用需要同时存储结构化数据和向量数据,你可能需要同时使用向量数据库和关系型数据库。由于Qdrant拥有较高的检索性能,且易于部署与使用,本文中我们将使用Qdrant作为我们的向量数据库。
CLIP模型简介
CLIP是一种多模态模型,通过对比目标学习将图像和文本关联起来。CLIP在一个大规模的图像及其相关文本(如图像说明)数据集上进行训练, 学习一个联合的Embedding Space,使语义相似的图像-文本对彼此接近。这个联合Embedding Space使CLIP能够执行各种视觉-语言任务,包括图像分类、目标检测和零样本学习。
CLIP由两个部分组成:图像编码器和文本编码器。它们分别可以将图像与文本编码为一个共享的Embedding Space中的向量。 通过在训练时让CLIP的图像编码器和文本编码器对齐,图像和文本的Embedding可以在同一个Embedding Space中进行比较。这也使得从文本来搜索对应的图像成为可能。
实现
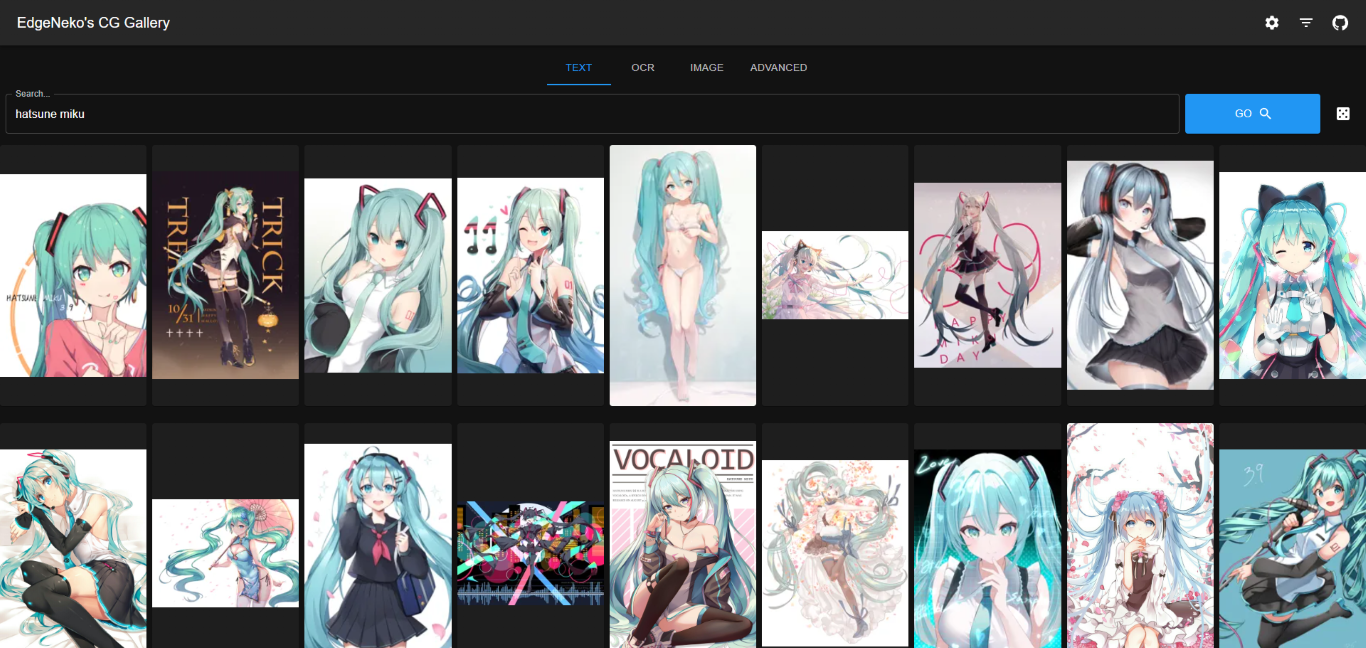
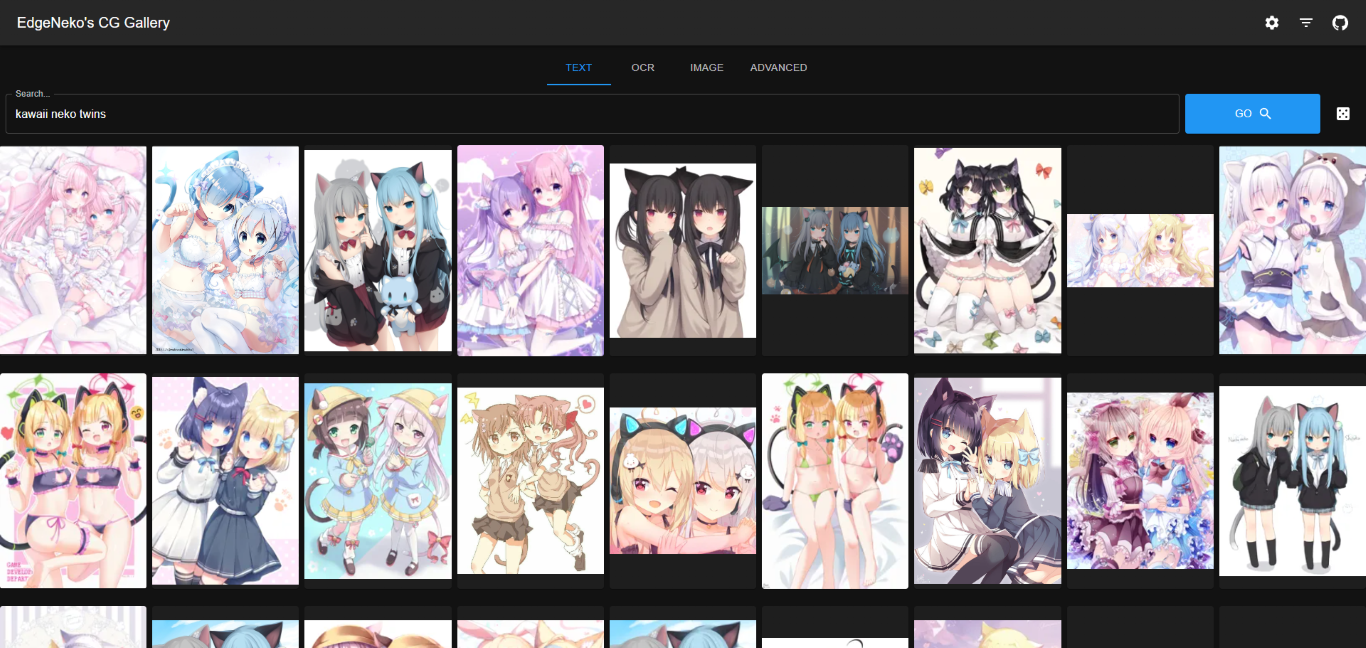
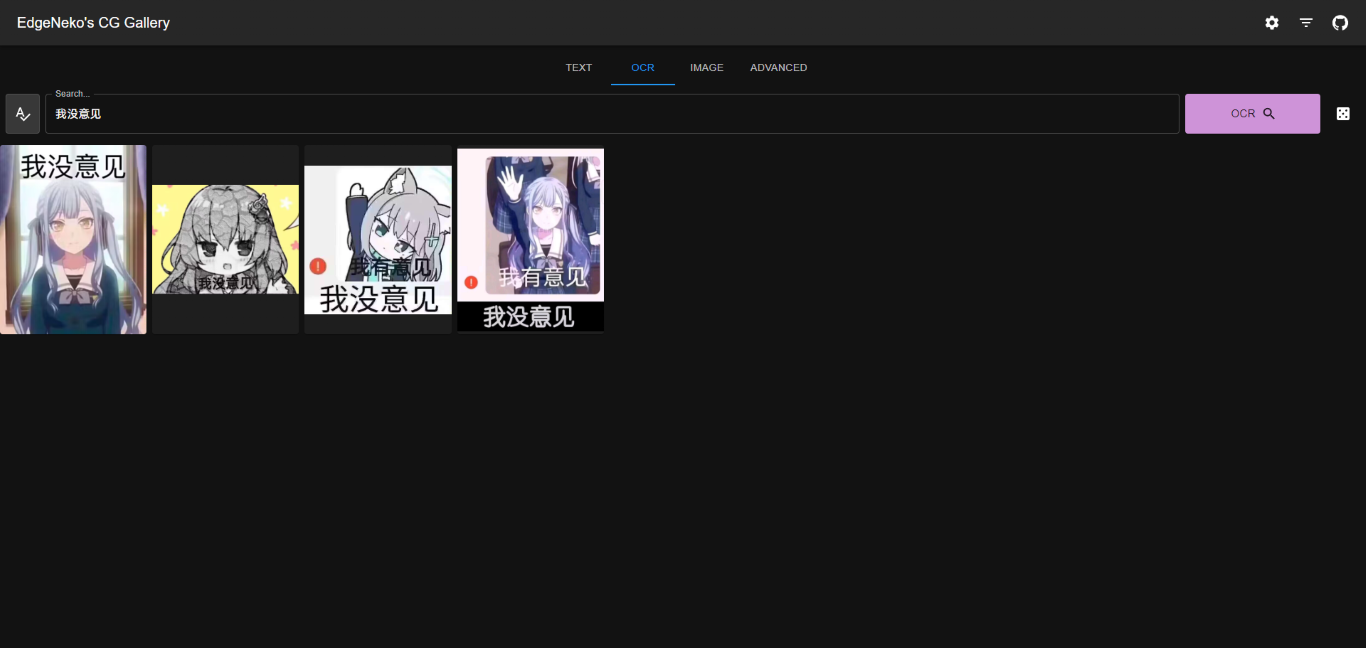
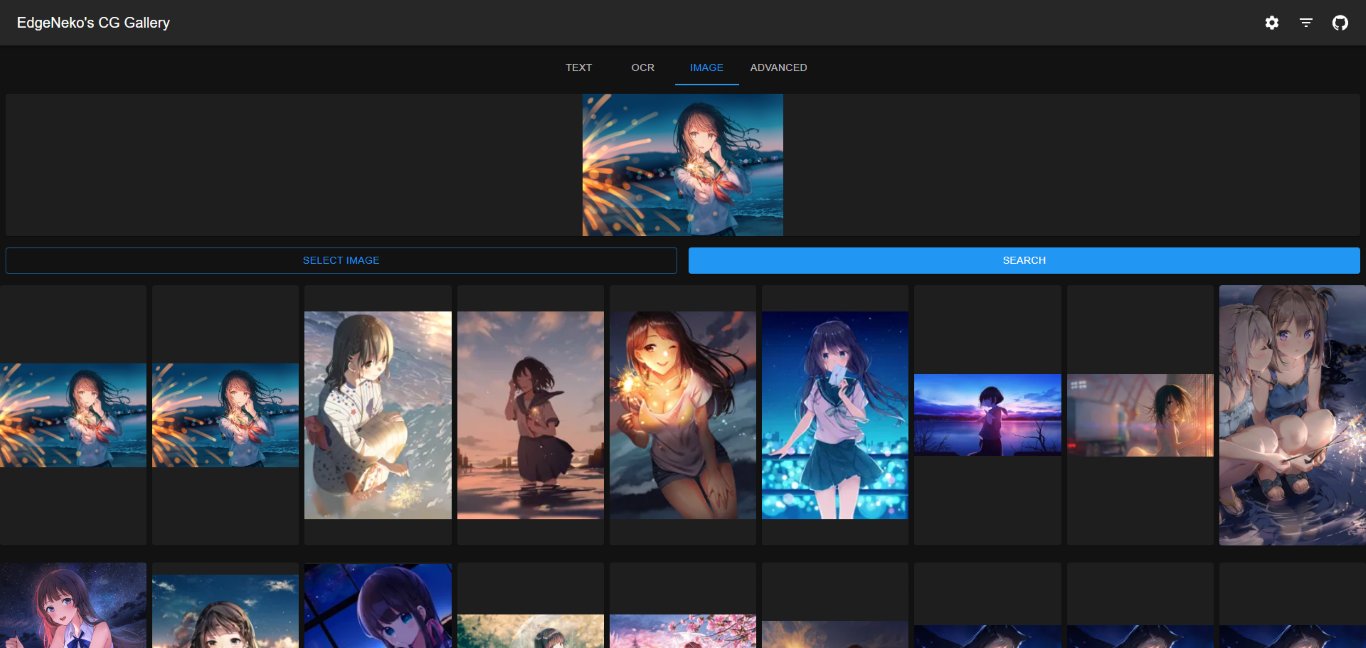
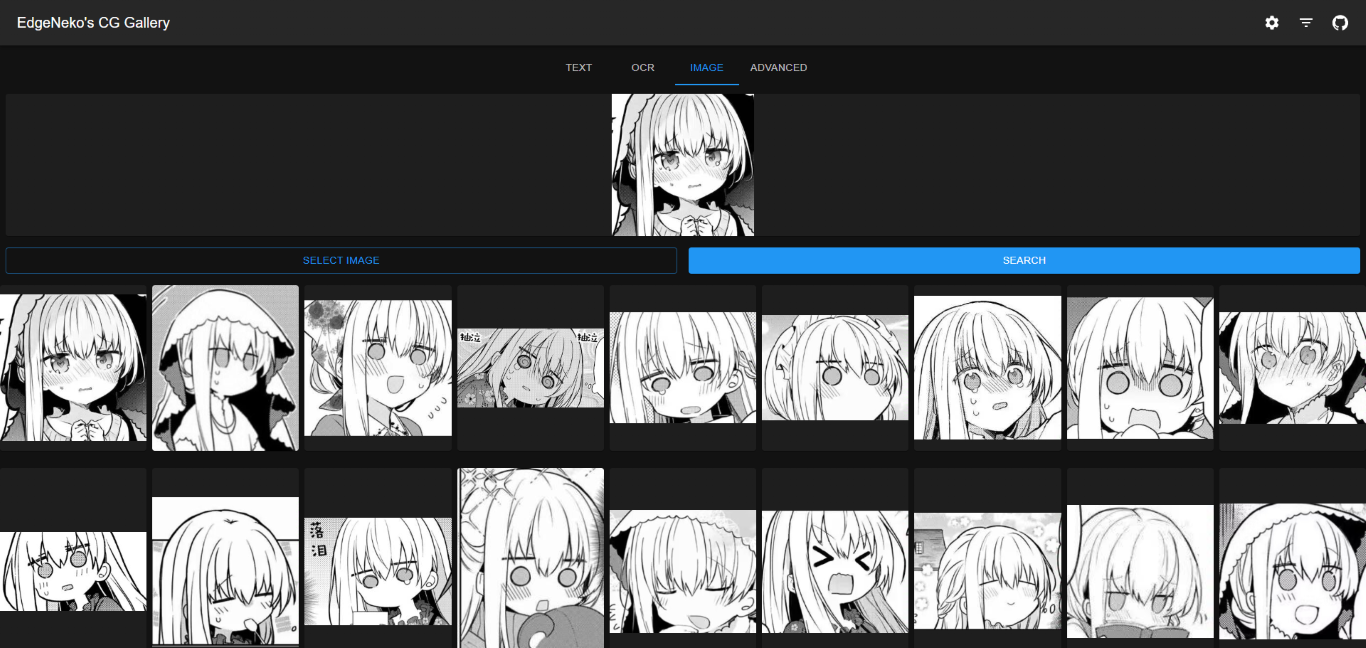
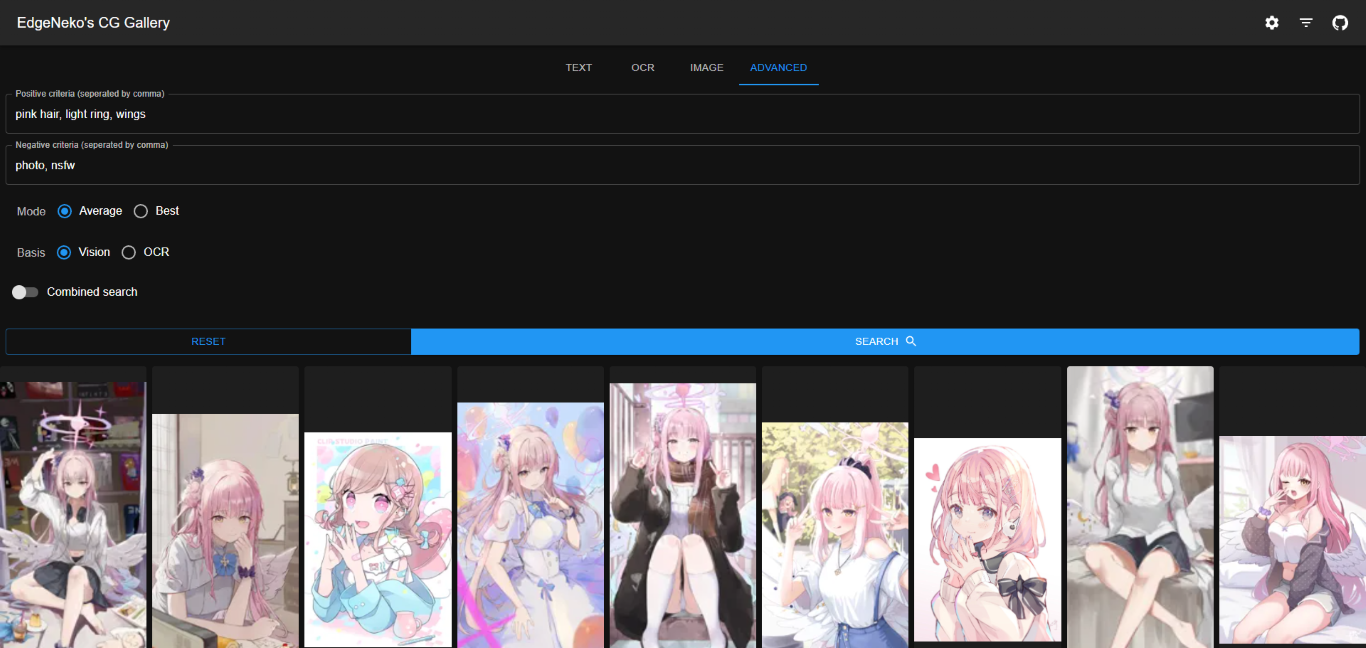
基于Clip的图片搜索引擎都已经实现在了NekoImageGallery中,你可以在这里尝试部署并体验强大的图片搜索功能。
这个项目中使用了Huggingface Transformers库完成Clip模型(用于文搜图和图搜图)和Bert模型(用于OCR搜索)的推理,以及Qdrant作为向量数据库存储所有图片的元数据。项目的源代码已经开源在了GitHub中。